1. Candy Crush Saga¶
Candy Crush Saga is a hit mobile game developed by King (part of Activision|Blizzard) that is played by millions of people all around the world. The game is structured as a series of levels where players need to match similar candy together to (hopefully) clear the level and keep progressing on the level map. If you are one of the few that haven't played Candy Crush, here's a short demo:
Candy Crush has more than 3000 levels, and new ones are added every week. That is a lot of levels! And with that many levels, it's important to get level difficulty just right. Too easy and the game gets boring, too hard and players become frustrated and quit playing.
In this project, we will see how we can use data collected from players to estimate level difficulty. Let's start by loading in the packages we're going to need.
# This sets the size of plots to a good default.
options(repr.plot.width = 5, repr.plot.height = 4)
# Loading in packages
library(readr)
library(dplyr)
library(ggplot2)
library(scales)
library(testthat)
library(IRkernel.testthat)
run_tests({
test_that("the packages are loaded", {
expect_true( all(c("package:ggplot2", "package:readr", "package:dplyr") %in% search() ),
info = "The dplyr, readr and ggplot2 packages should be loaded using library().")
})
})
2. The data set¶
The dataset we will use contains one week of data from a sample of players who played Candy Crush back in 2014. The data is also from a single episode, that is, a set of 15 levels. It has the following columns:
- player_id: a unique player id
- dt: the date
- level: the level number within the episode, from 1 to 15.
- num_attempts: number of level attempts for the player on that level and date.
- num_success: number of level attempts that resulted in a success/win for the player on that level and date.
The granularity of the dataset is player, date, and level. That is, there is a row for every player, day, and level recording the total number of attempts and how many of those resulted in a win.
Now, let's load in the dataset and take a look at the first couple of rows.
# Reading in the data
data <- read_csv("datasets/candy_crush.csv")
# Printing out the first six rows
head(data, 6)
run_tests({
test_that("data is read in correctly", {
correct_data <- read_csv("datasets/candy_crush.csv")
expect_equal(correct_data, data,
info = "data should countain datasets/candy_crush.csv read in using read_csv")
})
})
3. Checking the data set¶
Now that we have loaded the dataset let's count how many players we have in the sample and how many days worth of data we have.
# Count and display the number of unique players
print("Number of players:")
length(unique(data$player_id))
# Display the date range of the data
data$dt <- as.Date(data$dt)
print("Period for which we have data:")
cat("from ", as.character(min(data$dt)), "until ", as.character(max(data$dt)))
run_tests({
test_that("nothing", {
expect_true(TRUE, info = "")
})
})
4. Computing level difficulty¶
Within each Candy Crush episode, there is a mix of easier and tougher levels. Luck and individual skill make the number of attempts required to pass a level different from player to player. The assumption is that difficult levels require more attempts on average than easier ones. That is, the harder a level is, the lower the probability to pass that level in a single attempt is.
A simple approach to model this probability is as a Bernoulli process; as a binary outcome (you either win or lose) characterized by a single parameter pwin: the probability of winning the level in a single attempt. This probability can be estimated for each level as:
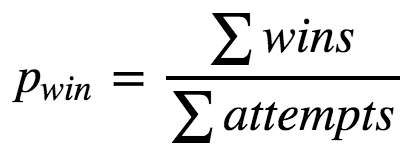
For example, let's say a level has been played 10 times and 2 of those attempts ended up in a victory. Then the probability of winning in a single attempt would be pwin = 2 / 10 = 20%.
Now, let's compute the difficulty pwin separately for each of the 15 levels.
# Calculating level difficulty
difficulty <- data %>%
group_by(level) %>%
dplyr::summarise(attempts = sum(num_attempts), wins = sum(num_success)) %>%
mutate(p_win = wins / attempts)
# Printing out the level difficulty
print(difficulty[c("level", "p_win")])
run_tests({
test_that("p_win is calculated correctly", {
correct_difficulty <- data %>%
group_by(level) %>%
summarise(attempts = sum(num_attempts), wins = sum(num_success)) %>%
mutate(p_win = wins / attempts)
expect_equal(correct_difficulty$p_win, difficulty$p_win,
info = "difficulty$p_win should be estimated probability to pass each level in a single attempt")
})
})
5. Plotting difficulty profile¶

Great! We now have the difficulty for all the 15 levels in the episode. Keep in mind that, as we measure difficulty as the probability to pass a level in a single attempt, a lower value (a smaller probability of winning the level) implies a higher level difficulty.
Now that we have the difficulty of the episode we should plot it. Let's plot a line graph with the levels on the X-axis and the difficulty (pwin) on the Y-axis. We call this plot the difficulty profile of the episode.
# Plotting the level difficulty profile
difficulty$level <- as.factor(difficulty$level)
ggplot(data=difficulty, aes(x=level, y=p_win, group=1)) +
geom_line()+
geom_point() +
scale_y_continuous(labels = scales::percent) +
labs(y= "Probability of winning", x = "Level")

run_tests({
test_that("the student plotted a ggplot", {
expect_true('ggplot' %in% class(last_plot()),
info = "You should plot difficulty using ggplot.")
})
})
6. Spotting hard levels¶
What constitutes a hard level is subjective. However, to keep things simple, we could define a threshold of difficulty, say 10%, and label levels with pwin < 10% as hard. It's relatively easy to spot these hard levels on the plot, but we can make the plot more friendly by explicitly highlighting the hard levels.
# Adding points and a dashed line
difficulty$level <- as.factor(difficulty$level)
ggplot(data=difficulty, aes(x=level, y=p_win, group=1)) +
geom_line()+
geom_point() +
scale_y_continuous(labels = scales::percent) +
labs(y= "Probability of winning", x = "Level") +
geom_hline(yintercept=0.10, linetype='dashed', col = 'red')

run_tests({
plot_layers <- sapply(last_plot()$layers, function(layer) class(layer$geom)[1])
test_that("the student has plotted lines, points and a hline", {
expect_true(all(c('GeomLine', 'GeomPoint', 'GeomHline') %in% plot_layers),
info = "The plot should include lines between the datapoints, points at the datapoints and a horisontal line.")
})
})
7. Computing uncertainty¶

As Data Scientists we should always report some measure of the uncertainty of any provided numbers. Maybe tomorrow, another sample will give us slightly different values for the difficulties? Here we will simply use the Standard error as a measure of uncertainty:
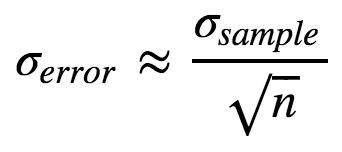
Here n is the number of datapoints and σsample is the sample standard deviation. For a Bernoulli process, the sample standard deviation is:
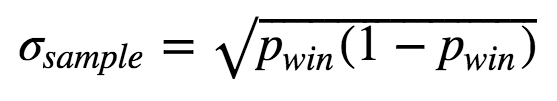
Therefore, we can calculate the standard error like this:
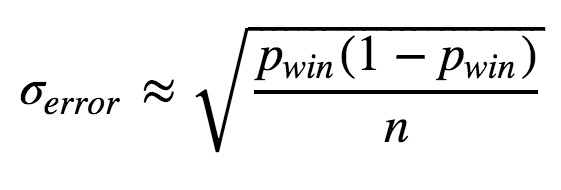
We already have all we need in the difficulty data frame! Every level has been played n number of times and we have their difficulty pwin. Now, let's calculate the standard error for each level.
# Computing the standard error of p_win for each level
difficulty <- difficulty %>%
mutate(error = sqrt(p_win * (1 - p_win) / attempts))
print(difficulty)
run_tests({
test_that("error is correct", {
correct_difficulty <- difficulty %>%
mutate(error = sqrt(p_win * (1 - p_win) / attempts))
expect_equal(correct_difficulty$error, difficulty$error,
info = "difficulty$error should be calculated as sqrt(p_win * (1 - p_win) / attempts)")
})
})
8. Showing uncertainty¶
Now that we have a measure of uncertainty for each levels' difficulty estimate let's use error bars to show this uncertainty in the plot. We will set the length of the error bars to one standard error. The upper limit and the lower limit of each error bar should then be pwin + σerror and pwin - σerror, respectively.
# Adding standard error bars
difficulty$level <- as.factor(difficulty$level)
ggplot(data=difficulty, aes(x=level, y=p_win, group=1)) +
geom_line()+
geom_point() +
scale_y_continuous(labels = scales::percent) +
labs(y= "Probability of winning", x = "Level") +
geom_hline(yintercept=0.10, linetype='dashed', col = 'red') +
geom_errorbar(aes(ymin = p_win - error, ymax = p_win + error))

run_tests({
plot_layers <- sapply(last_plot()$layers, function(layer) class(layer$geom)[1])
test_that("the student has plotted lines, points and a hline", {
expect_true("GeomErrorbar" %in% plot_layers,
info = "The plot should include error bats using geom_errorbar.")
})
})
9. A final metric¶
It looks like our difficulty estimates are pretty precise! Using this plot, a level designer can quickly spot where the hard levels are and also see if there seems to be too many hard levels in the episode.
One question a level designer might ask is: "How likely is it that a player will complete the episode without losing a single time?" Let's calculate this using the estimated level difficulties!
# The probability of completing the episode without losing a single time
p <- prod(difficulty$p_win)
# Printing it out
p
run_tests({
test_that("p is correct", {
correct_p <- prod(difficulty$p_win)
expect_equal(correct_p, p,
info = "p should be calculated as the product of difficulty$p_win .")
})
})
10. Should our level designer worry?¶
Given the probability we just calculated, should our level designer worry about that a lot of players might complete the episode in one attempt?
# Should our level designer worry about that a lot of
# players will complete the episode in one attempt?
should_the_designer_worry = FALSE
run_tests({
test_that("should_the_designer_worry is FALSE", {
expect_false(should_the_designer_worry,
info = "The probability is really small, so I don't think the designer should worry that much...")
})
})